
CHIASMA Partners from Hanyang University in South Korea have published a paper entitled ‘AI-based nanotoxicity data extraction and prediction of nanotoxicity’, in which they report the development of an AI-driven automated pipeline capable of extracting nanotoxicity data from scientific literature to significantly reducing the time and effort required for data collection.
The team implemented the automation process in Python-based LangChain, and trained their large language model (LLM) on 216 nanotoxicity research articles. Subsequently, the most suitable LLM with refined prompts was used to extract test data from 605 research articles.
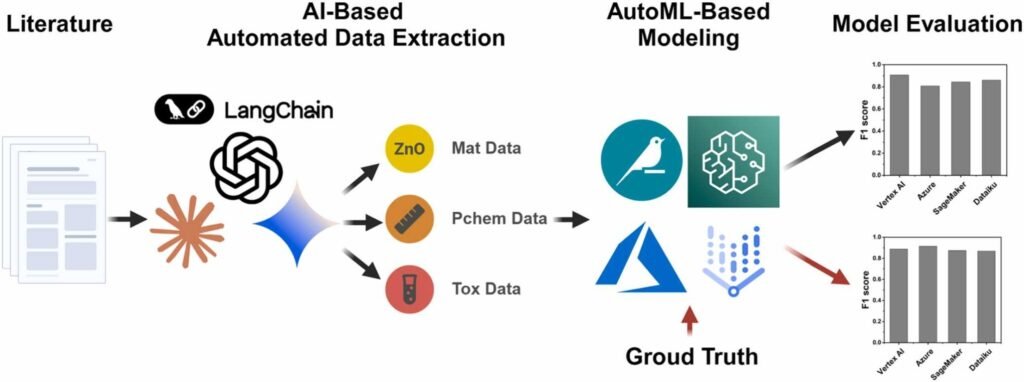
The new AI-based method shows a data extraction performance on training data achieved ranging from 84.6 % to 87.6 % across different LLMs, while the automated machine learning (AutoML) models using test sets achieved a score for Nanotoxicity Prediction exceeding 86.1%. Additionally, the team assessed the reliability and applicability of models by comparing them in terms of ground truth, size, and balance.
The researchers show that their pipeline efficiently extracted key physicochemical and toxicological properties, producing high-quality datasets for model training. Notably, a comparative analysis identified ChatGPT-4o as the most effective model for this purpose, highlighting its utility in nanotoxicity research. Furthermore, applying these datasets in AutoML platforms enabled the development of prediction models with performance comparable to manually curated methods, while also expanding the applicability domain. This allows researchers to more comprehensively evaluate potential toxicity risks of NMs.
The full paper can be accessed here (open access).




